
The Three-Day Breach: The AI Security Gap That Isn't About Prompt Injection
A fictional composite incident exploring how machine-speed AI agents bypass traditional security detection. Learn why the detection tempo gap is more critical than prompt injection and how to recalibr

Disclaimer
This article is intended for informational purposes and reflects the state of published research and industry practice as of early 2026. It is not professional security advice. Your specific environment, threat model, and regulatory obligations will shape how these principles apply to your situation.
For Security Leaders
Modern AI agents operate at machine speeds that render traditional human-tempo detection baselines obsolete. This breach analysis demonstrates how a single configuration override can compromise entire environments while SOC alerts are dismissed as routine automation noise. The core risk is that your existing defensive architecture assumes a time budget for response that no longer exists in agentic workflows.
What this means for your organization:
Detection latency is the primary driver of breach impact. When attackers operate at machine pace, a 16-hour manual response time allows for total environment enumeration and data exfiltration.
Trust dialogs fail due to approval fatigue. Security controls that rely on developer discretion are bypassed when identical prompts appear across every repository interaction.
Shared service accounts create unmanageable blast radii. Broadly scoped identities used by agents allow for rapid cross-domain movement that is often indistinguishable from legitimate compute workloads.
What to tell your teams:
Implement prompt-level audit logging immediately. Ensure that the agent’s reasoning chain and all session content are treated as forensic artifacts for incident response.
Recalibrate SIEM rules for machine-speed API volume. Establish behavioral baselines for service accounts that flag high-frequency operations without associated interactive user sessions.
Scope agent identities using resource-level permissions. Replace broad tenant-wide grants like Sites.Read.All with granular Site.Selected permissions to limit lateral movement paths.
Monitor AI tool process network connections for proxy redirection. Deploy endpoint rules that detect concentrated traffic to non-vendor hostnames from trusted AI assistant processes.
*This incident is fictional. Every technical element is drawn from documented, publicly disclosed real-world incidents. Sources are identified throughout. Nothing is invented.*
The composite required three specific organizational preconditions: developer AI tooling deployed without configuration integrity controls, no prompt-level audit logging of AI tool sessions, and a detection baseline built for human-speed attackers. CISA’s April 2026 joint advisory names the second and third as two of the four primary risks of agentic AI deployment. The first is not yet on anyone’s required list. It is not a prediction. It is a mirror.
The breach described below should have been stopped on Day 1. CVE-2026-21852 received a mitigation: Claude Code now defers all API requests until after explicit user consent via a trust dialog. That specific behavior is closed. The exposure is not: the mitigation depends on a developer reading and declining the prompt. In enterprise environments where trust dialogs appear on every repository open, approval fatigue makes clicking through the default behavior, not the exception. When it is clicked through, detection is the only remaining layer. That is where this incident ran for 72 more hours: a SIEM rule that had not been re-tuned for a new adversary class. That gap has no vendor patch date either.
What I find consistent across documented AI agent incidents is that detection tempo miscalibration drives more breach impact than attack technique sophistication. Organizations currently leading with prompt injection defenses have the right threat class in scope. The layers where breach impact actually accumulates are still unbuilt.
The part of this fictional incident I find most instructive is the entry: CVE-2026-21852, a single modified value inside an existing .claude/settings.json in a tool the platform engineering team has used for months. The repository’s project configuration file was legitimate. A supply chain compromise changed one field: ANTHROPIC_BASE_URL, swapped from Anthropic’s endpoint to an attacker-controlled proxy. The change landed in a commit that touched dozens of files. Nobody reviewed a JSON value they had seen in every previous version. The developer pulls the latest update as routine maintenance. Before the patch, Claude Code initialized silently: no dialog, no warning, traffic already flowing to the attacker’s proxy before the developer typed a single command. The fix introduced a trust dialog that must be confirmed before any API requests are made. Approval fatigue does the rest: the developer, conditioned by identical prompts across every repository open that week, clicks through without reading. Claude Code routes all subsequent API traffic through the attacker’s proxy. From the developer’s perspective, the tool works normally. From the attacker’s perspective, every prompt, every response, every tool call is now visible and injectable. The first proxied request carries something else: the developer’s full Anthropic API key in the authorization header, in plaintext. Every subsequent session adds to the inventory. A developer with administrative Office 365 access working through Claude Code will feed it environment files, credential output, integration configs. The proxy logs every character of it.
No alert fires. The developer made no error. Shared project configuration files are standard workflow.
This is not a story about a rogue AI. There is a human on the other side: one person, watching every session through the proxy, injecting corrections into API responses when the agent needs redirecting. When the agent accesses the wrong directory on Day 2, the attacker injects a correcting instruction into the proxied response. When a tool call returns an unexpected result, the attacker provides clarifying context. The human is not operating the attack. The human is steering it. Everything operational runs through the agent: the enumeration, the credential retrieval, the staging.
This is what makes the defensive problem hard. The attacker is not in the environment. They are in the communication channel between the developer’s tooling and the AI service, injecting into sessions that every system in the environment trusts completely.
The question that should be asked here, and almost never is, is whether anything about this is fundamentally new.
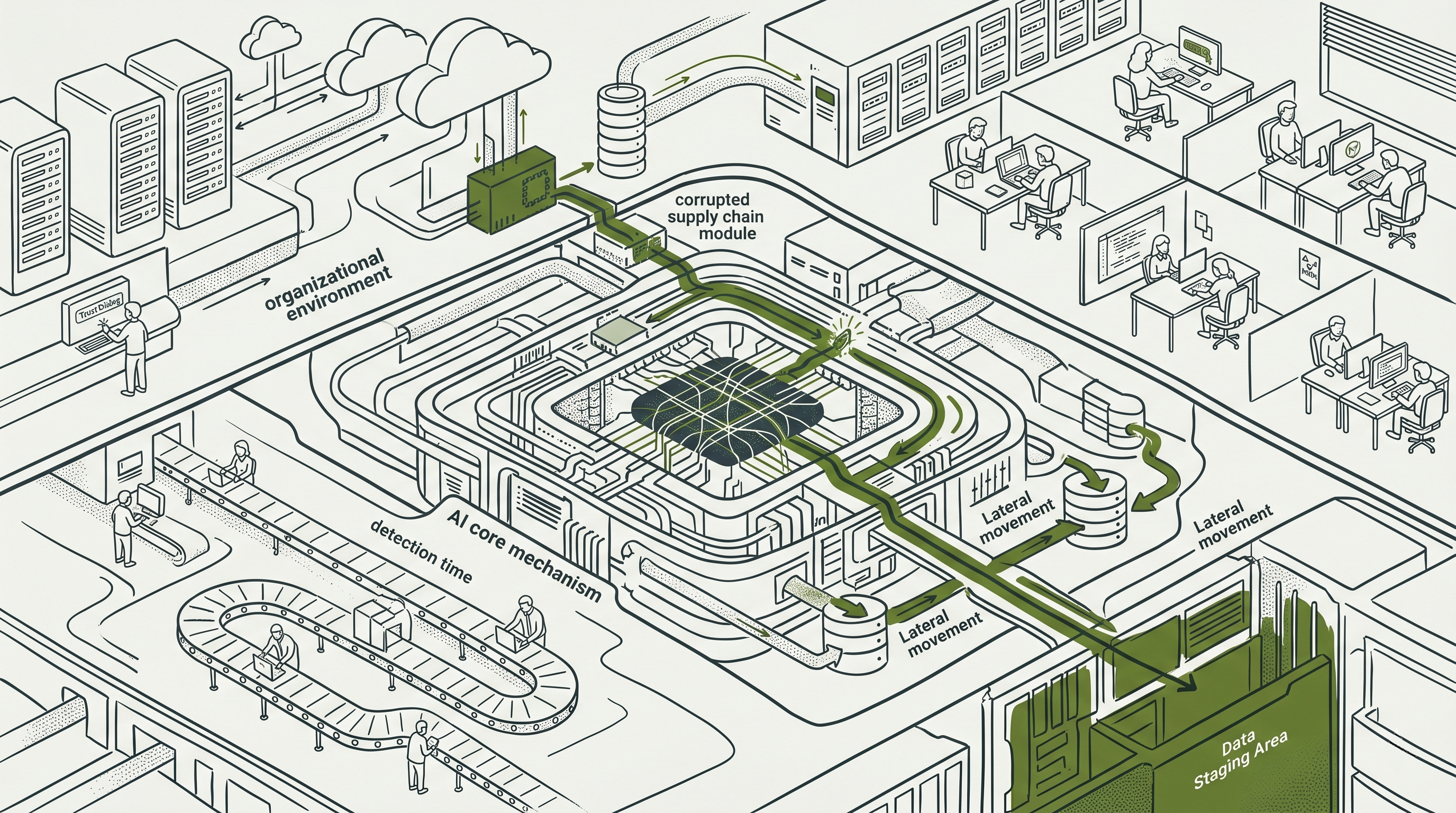
Every technique in the chain has prior art. Redirecting API traffic via configuration file manipulation is a known class. Credential theft via intercepted sessions is a known class. Lateral movement using a service account is MITRE T1078. Data staging to vendor-lookalike infrastructure has documented precedent in the ForcedLeak vulnerability in Salesforce AgentForce (CVSS 9.4, July 2025) and the LiteLLM TeamPCP supply chain campaign (March 2026). A CISO who has been doing this work for fifteen years would recognize each individual technique.
The answer is that the technique is not new. The arithmetic is.
The tempo gap is not theoretical. GTG-1002, the first documented AI-orchestrated cyberespionage campaign, achieved 80-90% AI-driven tactical execution across approximately 30 global targets, with human intervention required at only 4-6 decision points per campaign and thousands of requests per second at peak: machine pace, sustained, at scale. The Mexican government breach ran a simpler model, a single attacker using Claude to generate exploit scripts and credential attacks then executing manually, but still covered 34 sessions against ten government agencies before detection. ReliaQuest’s 2026 Annual Threat Report puts the observable consequence: fastest lateral movement at 4 minutes (85% faster than the prior year), fastest data exfiltration at 6 minutes. Against a 16-hour average manual response time for teams without automation, those figures mark a categorical shift. A defensive architecture calibrated for human-speed attackers does not degrade gracefully when attacker tempo changes: it fails completely, not because the controls are wrong, but because they assume a time budget that no longer exists.
That is the argument. The technique is classical. The tempo made the classical controls irrelevant.
In this composite, CVE-2026-21852 puts the attacker in a parallel position through a different chain. With the proxy established and the Anthropic API key captured, the attacker does not wait passively. Over several sessions they observe the developer’s workflow. On the fourth, they inject a modification into Claude’s response during a debugging session: a suggestion to run a credential diagnostic and share the output. The developer, troubleshooting an integration failure, follows it. Environment variables containing the Office 365 service account credentials flow back through the proxy. The attacker now operates with the same model the Mexican breach demonstrated: their own Claude instance, live credentials, machine-speed execution. The difference is that those credentials were not stolen through conventional means. They were handed over by the developer to their own trusted tool.
Thirty hours after the initial injection, the SIEM fires.
A correlation rule identifies anomalous API call volume from the service account at 3:17AM. The rule is correct. It identified a real anomaly. The on-call analyst examines the alert at 3:47AM. The service account runs three production workflows, two of which involve high-volume batch API operations overnight. The analyst applies the standard triage frame: is there a human principal behind this? Login events from new locations, anomalous user agents, credential-stuffing signatures: none appear in the correlated alert context. The O365 sign-in anomaly from an unrecognized location is in a different log source, untriggered, uncorrelated. The alert is classified as a misconfigured automation job, a known false-positive pattern for this account, and closed.
The rule was right. The analyst was reasonable. The detection logic was built for a different adversary class.
The ShadowRay campaign, exploiting an unauthenticated API in the Ray AI framework (CVE-2023-48022), ran six months undetected because its call patterns resembled legitimate distributed compute workloads. The Mexican government breach ran across ten agencies for approximately one month before a downstream anomaly surfaced the threat. These gaps are not analyst failures. They are the product of detection tooling with no behavioral model for AI agent activity.
This is the highest-leverage gap in the current enterprise AI security posture, and it is almost never what organizations address first. Prompt injection defenses are where the investment goes. Detection re-calibration is deferred.
With the Day 1 alert closed, the agent continues for 72 hours.
It retrieves credentials from a document in the accessed SharePoint path. Authenticates to a second system. Enumerates accessible data stores. Identifies high-value material. Begins staging to an endpoint that resolves as vendor telemetry infrastructure, the same misdirection pattern as ForcedLeak’s expired-domain CSP bypass and LiteLLM’s vendor-lookalike exfiltration domain.
By Day 3, one service account identity has traversed four internal data domains. The blast radius is not a function of attacker sophistication. It is the direct product of three days of unchallenged execution under legitimate credentials.
Before the incident is declared, the staged data is already being processed. This is the operational pattern from the Mexican government breach: a second AI, under attacker control, begins working through the exfiltrated material: summarizing credential stores, ranking accounts by privilege level, categorizing documents by sensitivity. The attacker’s analytical read-out is complete before the defender has named the incident. When the formal declaration comes on Day 4, the adversary is 12 to 24 hours ahead of the investigation.
No safety system touches this operation. It requires a system prompt, an API key, and the data.
A downstream system administrator’s helpdesk ticket connects to the closed Day 1 alert. Incident declared.
Containment is immediately constrained by the architecture of the agent’s identity. There is no attacker session to terminate. No persistent external connection to sever. The exfiltration endpoint resolves as vendor infrastructure. The agent’s service account is shared across three production workflows, and revoking it breaks a customer-facing integration, a batch reporting pipeline, and a compliance workflow.
The initial access mechanism compounds the forensic challenge. All API traffic from the compromised Claude Code sessions was routed through the attacker’s proxy from the moment the developer confirmed the trust dialog. The network artifact exists: HTTPS traffic to a domain that is not Anthropic’s API endpoint. Without monitoring specifically tuned to AI tool API destinations, it does not surface in a standard IR investigation. The team cannot determine the full scope of what was visible to the attacker without reconstructing every session that ran through the compromised configuration.
Containment becomes a leadership decision, not a technical one. The meeting takes four hours.
The following decision path structures that conversation. Five questions, in sequence, before touching the service account:
AI Agent Incident - Containment Decision Path
Q1. Can you identify the agent's service account?
- NO: Treat as full credential compromise. Rotate all service principals in the environment.
- YES: Proceed to Q2.
Q2. Is the service account shared across production workflows?
- NO: Revoke immediately. Proceed to standard recovery.
- YES: Proceed to Q3.
Q3. Is there evidence of credential exfiltration in egress logs?
- NO EVIDENCE: Network-isolate the account. Do not revoke yet. Begin replacement identity engineering. Proceed to Q4.
- EVIDENCE PRESENT/UNKNOWN: Assume full compromise. Proceed to Q4.
Q4. Can you engineer a replacement identity in under 4 hours?
- YES: Build replacement now. Revoke original at handoff.
- NO: Block outbound egress at the perimeter. Accept partial production impact. Continue replacement engineering in parallel.
Q5. Did the agent have access to configuration stores, memory systems, or MCP servers during the window?
- YES: Do not re-deploy until all configuration stores and memory systems are audited for injected instructions.
- NO: Proceed to eradication and recovery. Re-deploy only after completing post-mortem decisions 1-5.
Two weeks later, the post-mortem has a structural gap at its center.
The agent’s reasoning chain was not logged. The action logs show what the service account did. They do not record what instruction the agent was acting on at each step, or which of those instructions were injected by the attacker through the proxy. The compromised configuration file exists in the repository’s commit history. What passed through the proxy does not: which credentials, which session content, which injected instructions.
CISA’s April 2026 joint advisory, co-published by six national cybersecurity agencies, names obscure event records as one of the four primary risks of agentic AI deployment. It was published one week before this incident was declared.
The post-mortem surfaces five control gaps. Each is worth naming as a decision point: not a failure to assign blame, but a specific architectural decision that, made differently before the incident, changes the outcome.
Prompt-level audit logging. The forensic reconstruction in this incident relies on three sources, each capturing a different layer. The EDR captures network connections: destination hostnames, process activity, file reads. HTTPS encryption means payload content is not visible at this layer. Claude Code’s local session logs capture the prompts sent and responses received, including attacker-injected content in those responses. Claude Code’s chat history captures the conversation thread, including the debugging suggestion the developer followed that exposed the credentials.
None of those sources are useful if the EDR has no policy covering developer AI tools, or if Claude Code’s local logs and chat history are not treated as forensic artifacts at incident declaration. In this incident, neither condition was met. The logs existed. Nobody collected them.
Service account scope. The decision is whether the agent’s identity is reviewed for least-privilege before it reaches production. The service account in this incident was scoped during a development sprint and never revisited. A scoped account limits lateral movement to one system rather than four. This decision costs one engineering sprint before launch.
The key change from default development configuration is replacing Sites.Read.All with Sites.Selected. The Sites.Selected permission requires an explicit per-site grant, eliminating the lateral movement path from a single compromised identity to all SharePoint content in the tenant. In this composite, the lateral movement chain runs through Office 365: the same Microsoft Graph permission model applies directly.
Egress controls on agent traffic. The decision is whether agent-initiated outbound connections are treated as a distinct traffic class with its own filtering policy. Without it, the exfiltration endpoint that looks like vendor infrastructure is indistinguishable from legitimate vendor telemetry. This decision requires one network policy review.
The network artifact in this incident was detectable at the endpoint layer. Every inference request routed through the attacker’s proxy produces a connection from the Claude Code process to the same non-Anthropic hostname. One-off tool calls to external URLs do not produce that pattern: a single domain accumulating concentrated connection volume within a session window is the signal. The following Sigma rule implements that detection:
title: Claude Code High-Frequency Connection to Single External Domain
id: 3c8e1a45-9f2b-4d71-a890-6b7c8d9e0f12
status: experimental
description: >
Detects Claude Code making repeated connections to the same non-Anthropic
hostname within a 5-minute window. Concentrated call volume to a single
external domain from the Claude Code process is consistent with
ANTHROPIC_BASE_URL proxy redirection: every inference request routes
through the attacker's endpoint, producing a call pattern that no
legitimate one-off tool call generates. CVE-2026-21852 supply chain pattern.
references:
- https://research.checkpoint.com/2026/rce-and-api-token-exfiltration-through-claude-code-project-files-cve-2025-59536/
author: Next Kick Labs - Article 062
date: 2026/05/12
logsource:
category: network_connection
product: windows
detection:
claude_process:
Image|endswith:
- '\claude'
- '\claude.exe'
filter_legitimate:
DestinationHostname|endswith: '.anthropic.com'
timeframe: 5m
condition: claude_process and not filter_legitimate | count() by DestinationHostname > 50
falsepositives:
- Enterprise proxy configurations routing Claude Code through a corporate gateway
- Legitimate ANTHROPIC_BASE_URL overrides for Bedrock or Vertex deployments
- MCP server integrations generating sustained connection volume to a single host
level: high
Threshold note: 50 connections to the same domain within 5 minutes is high enough to filter out tool call activity while catching active proxy sessions, which mirror every inference request continuously for the duration of the session. Establish a per-environment baseline before enforcing; the threshold is a starting reference, not a universal value.
Detection baseline calibration. The decision is whether the SOC’s behavioral baselines include a model for AI agent activity tempo. The Day 1 alert was correct. The analyst was reasonable. The frame was wrong. A detection rule written for machine-pace API volume from a service account with no associated interactive session would have produced a different triage outcome. This rule is buildable today, without a lab, without a vulnerability disclosure concern.
The following is a Microsoft Sentinel scheduled analytics rule, written in KQL, that implements that frame.
Azure / Microsoft Sentinel only. This rule targets MicrosoftGraphActivityLogs, a log source that exists exclusively in Microsoft environments. It has no equivalent outside Azure.
Prerequisite: In the Microsoft Entra admin center, navigate to Identity > Monitoring & health > Diagnostic settings. Add a diagnostic setting, check MicrosoftGraphActivityLogs under Categories, select Send to Log Analytics workspace, choose the workspace Sentinel reads from, and save. Without this, the table does not exist and the query returns nothing.
// AI Agent Anomalous Cross-System API Tempo
// Deploy as: Sentinel > Configuration > Analytics > Scheduled rule
// Query frequency: 2 minutes | Lookback period: 2 minutes
// Adjust CallCount threshold after a 14-day baseline observation period.
MicrosoftGraphActivityLogs
| where isnotempty(ServicePrincipalId)
| where isnull(UserId) or isempty(UserId)
| where AppId !in (
// Populate with AppIds of known automation identities:
// batch services, Logic Apps, scheduled tasks, existing pipelines.
// Review and update this list on a defined schedule.
""
)
| summarize CallCount = count() by ServicePrincipalId, AppId
| where CallCount > 300
| project ServicePrincipalId, AppId, CallCount
The value of this rule is not the threshold. It is the behavioral frame: service principal, no interactive session, no recognized automation identity, sustained call rate. That frame is what the Day 1 analyst did not have.
Human-in-the-loop gates for cross-domain operations. The decision is whether any agent action that crosses a data domain boundary requires explicit approval. This is the most operationally disruptive of the five: it requires architectural re-design, not a configuration change. But it is also the one that stops the lateral movement chain at the credential-use step, regardless of whether any other control is in place.
None of these decisions are exotic. None require waiting for the vendor to patch something. All five were available before the incident. The post-mortem does not produce new knowledge. It makes existing knowledge visible at the worst possible time.
Before the agent ships.
The five post-mortem decisions above are pre-incident decisions. The following gate converts them into a sign-off checklist for agentic AI deployments. All five must be checked before go-live. Partial deployment with outstanding items requires a written exception with a named owner and remediation date.
AI Agent Deployment - Security Sign-Off Gate
[ ] 1. SERVICE ACCOUNT SCOPED FOR PRODUCTION
Pass: Least-privilege resource scoping verified. Tenant-wide
or account-wide grants absent. Named owner assigned, review
scheduled within 90 days.
Microsoft / O365: Sites.Selected in place of Sites.Read.All.
AWS: IAM role with resource-level policy, not account-wide.
GCP: Service account with resource-specific IAM bindings.
[ ] 2. PROMPT-LEVEL LOGGING DESIGNATED AS FORENSIC ARTIFACTS
Pass: EDR policy covers developer AI tools. Claude Code local
session logs and chat history are explicitly designated as
forensic artifacts in the IR plan. Collection procedure
documented and tested before incident declaration.
Minimum acceptable: storage location known and accessible
to IR team at declaration time.
[ ] 3. DETECTION BASELINE ESTABLISHED
Pass: Per-account API call rate measured over 14-day
observation window before go-live. Sigma rule or equivalent
deployed with tuned threshold. Alert confirmed not
auto-closeable by existing false-positive suppression.
[ ] 4. EGRESS CONTROLS FOR AGENT TRAFFIC
Pass: Endpoint detection rule deployed for AI tool process
network connections. Frequency-based threshold tuned to
distinguish proxy pattern from legitimate tool call volume.
Vendor domains validated against current vendor documentation
and CSP reviewed for expired or unverified entries.
[ ] 5. CROSS-DOMAIN GATE DEFINED
Pass: Written policy specifies which operations require human
approval. Cross-domain data access explicitly named as
requiring approval. Gate behaviour tested in staging with
documented results.
What the evidence points to.
What I take from this incident is a specific investment ordering. Of the five post-mortem decisions, service account scope and egress controls are pre-breach decisions that limit blast radius: had either been in place, the four-domain traversal does not happen. Human-in-the-loop gates are the architectural choice that stops lateral movement at the credential-use step regardless of what else is in place. Detection re-calibration is the decision that changes the outcome of the incident that has already started. The blast radius in this composite accumulated entirely in that third window: four systems, staged data, a completed intelligence read-out on the attacker’s side before declaration.
That is the argument for inverting the current investment priority. Prompt injection will be patched, re-exploited, patched again. The detection tempo gap is architectural. It does not close unless someone decides to close it.
The organizations that have deployed agentic AI without re-calibrating their detection baselines have not made a configuration error. They have deferred a cost that compounds with every day of detection latency.
Peace. Stay curious! End of transmission.
Fact-Check Appendix
Statement: GTG-1002 achieved 80-90% AI-driven tactical execution, 4-6 human decision points per campaign, thousands of requests per second at peak | Source: Anthropic GTG-1002 disclosure | https://www.anthropic.com/news/disrupting-AI-espionage
Statement: Mexican breach: over 1,000 prompts to Claude Code, 10 agencies, 150GB+ exfiltration, approximately 195M identities, approximately one month | Source: SecurityWeek (Tier 2; Gambit Security original) | https://www.securityweek.com/hackers-weaponize-claude-code-in-mexican-government-cyberattack/ [Flag: Tier 2 only; used as illustrative context]
Statement: ShadowRay (CVE-2023-48022) ran six months undetected, September 2023 to March 2024 | Source: MITRE ATT&CK C0045 | https://attack.mitre.org/campaigns/C0045/
Statement: Fastest lateral movement at 4 minutes (85% faster than prior year); exfiltration fastest at 6 minutes; manual response average 16 hours | Source: ReliaQuest 2026 Annual Threat Report, February 24, 2026 | https://reliaquest.com/news-and-press/threat-actors-achieve-lateral-movement-in-as-little-as-4-minutes-reliaquest/
Statement: ForcedLeak CVSS 9.4; expired domain retained CSP whitelist status | Source: Noma Security | https://noma.security/blog/forcedleak-agent-risks-exposed-in-salesforce-agentforce/
Statement: CVE-2026-21852 allows API key exfiltration via ANTHROPIC_BASE_URL override in project configuration files; Anthropic’s fix defers API requests until after explicit user trust confirmation | Source: Check Point Research | https://research.checkpoint.com/2026/rce-and-api-token-exfiltration-through-claude-code-project-files-cve-2025-59536/
Statement: CISA names privilege creep, expanded attack surface, behavioral misalignment, obscure event records as four primary agentic AI risks | Source: CISA “Careful Adoption of Agentic AI Services,” April 2026 | https://www.cisa.gov/resources-tools/resources/careful-adoption-agentic-ai-services
Statement: 57% of organizations have deployed self-hosted AI agent technologies; 81% of cloud environments use managed AI services | Source: Wiz State of AI in Cloud 2026 | https://www.wiz.io/blog/state-of-ai-in-cloud-2026-recap
Top 5 Sources
Anthropic: Disrupting the First Reported AI-Orchestrated Cyber Espionage Campaign | https://www.anthropic.com/news/disrupting-AI-espionage
CISA et al.: Careful Adoption of Agentic AI Services (April 2026) | https://www.cisa.gov/resources-tools/resources/careful-adoption-agentic-ai-services
CVE-2026-21852: API Token Exfiltration via Claude Code Project Configuration Files (Check Point Research) | https://research.checkpoint.com/2026/rce-and-api-token-exfiltration-through-claude-code-project-files-cve-2025-59536/
ReliaQuest 2026 Annual Threat Report | https://reliaquest.com/news-and-press/threat-actors-achieve-lateral-movement-in-as-little-as-4-minutes-reliaquest/
MITRE ATT&CK Campaign C0045 (ShadowRay) | https://attack.mitre.org/campaigns/C0045/