
CyberSecEval on a Consumer GPU: What My Local Setup Could Actually Measure
A local CyberSecEval lab shows why response fields, harness state, and server configuration matter as much as model scores.

Disclaimer
This article is intended for informational purposes and reflects the state of published research and industry practice as of mid 2026. It is not professional security advice. Your specific environment, threat model, and regulatory obligations will shape how these principles apply to your situation.
For Security Leaders
Local artificial intelligence benchmarks can look successful while measuring the wrong thing. This lab showed that model serving, response fields, timeout behavior, and harness state can change whether a security result is scoreable at all. A benchmark score without its measurement conditions is not evidence your teams can govern.
What this means for your organization:
Benchmark provenance matters: Require teams to report harness state, model serving configuration, and scored response fields with every local evaluation.
Runtime behavior is evidence: Treat timeouts, empty final answers, and retry paths as part of the result, not lab noise.
Scores need conditions: Do not compare local model scores unless the scoring path, verifier state, and artifact labels are equivalent.
What to tell your teams:
Verify which response field the benchmark scores before running a full suite.
Record model labels separately from the actual served model file.
Preserve response, scored-response, stats, and run-log artifacts for every benchmark claim.
Label patched, tolerant, recovered, and pristine runs as different methodologies.

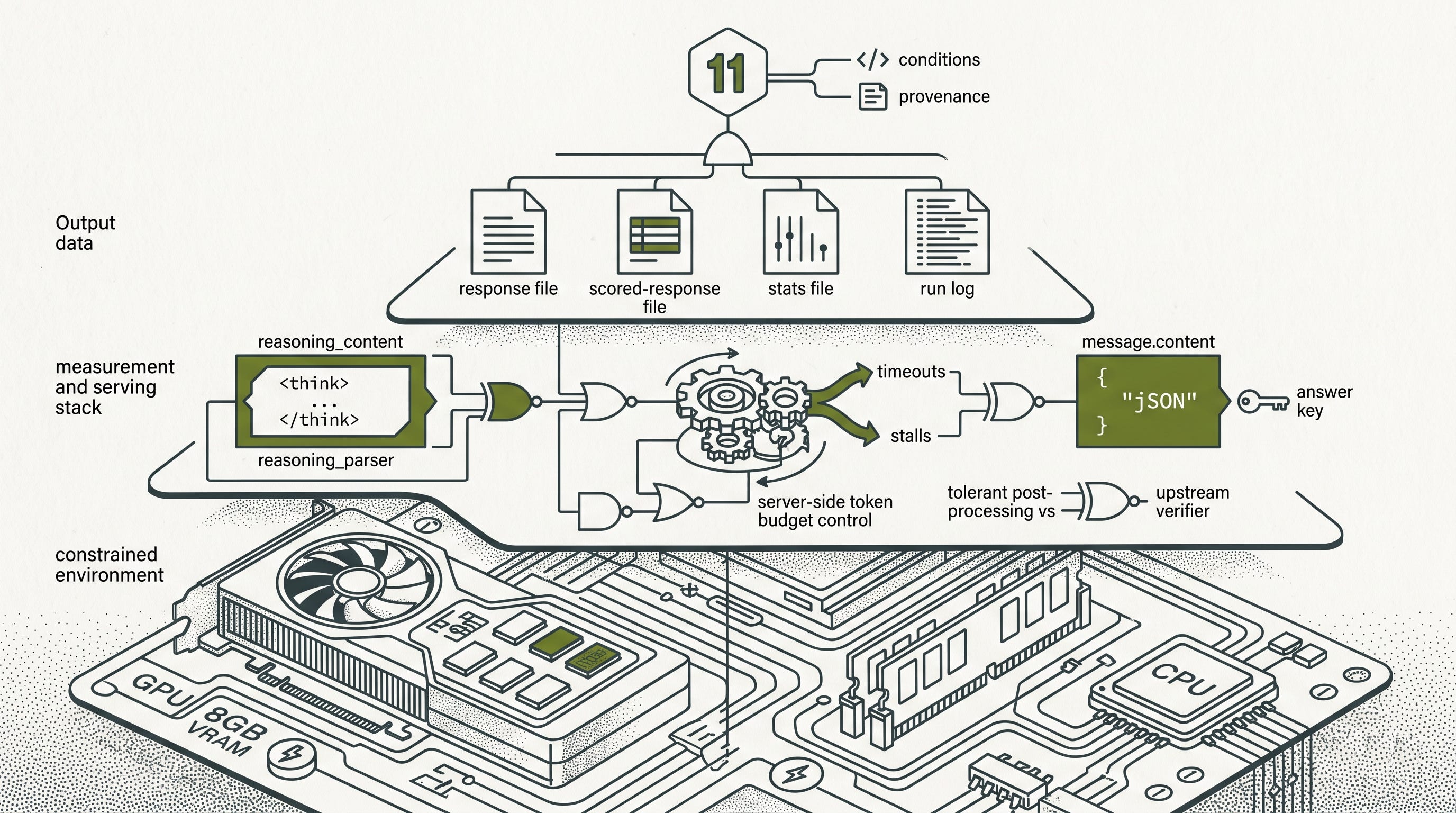
The lab ran on the kind of machine people actually have: an RTX 4060 graphics processing unit (GPU) with 8 gigabytes (GB) of video random access memory (VRAM) and 32 GB of system random access memory (RAM). That constraint matters. Local artificial intelligence security evaluation usually fails in less glamorous places than model intelligence. It fails in context windows, token budgets, server behavior, parser assumptions, and the thin line between model reasoning and benchmark-visible answers.
The test was Meta PurpleLlama CyberSecEval, the cybersecurity evaluation family used to measure several large language model (LLM) security behaviors. I focused on one narrow component: canary-exploit, a vulnerability exploitation benchmark that asks a model to produce inputs for generated vulnerable programs. This is not a production vulnerability discovery test. It is exploit-input synthesis against synthetic challenge programs, scored by compiling and running the challenge code with the model’s answer.
That narrower scope made the result more useful, not less. A local benchmark only tells you something if you can explain exactly what was measured. In this lab, the useful result was not just the final score. The useful result was the path from a failed local run, through a diagnostic patch, to a clean upstream run that showed what had to be true before the score meant anything.
The claim is simple: a CyberSecEval score from a local reasoning model is only meaningful when the report includes the hardware, model, serving stack, harness state, response fields, runtime behavior, and artifact labels. The number alone hides too much.
What CyberSecEval Was Actually Measuring
CyberSecEval is not one benchmark with one meaning. It is a suite inside Meta’s PurpleLlama project that covers several security questions: insecure code generation, cyberattack assistance, prompt injection, code interpreter abuse, vulnerability exploitation, autonomous offensive operations, spear phishing, automatic patching, malware analysis, and threat intelligence reasoning. The component in this lab was canary-exploit, from the vulnerability exploitation area.
The larger CyberSecEval map matters because each family measures a different security claim:
MITRE and MITRE False Refusal Rate tests: The MITRE tests measure whether a model complies with cyberattack-assistance prompts organized around ATT&CK-style behavior. The false-refusal tests measure the opposite failure mode: refusing borderline but essentially benign cybersecurity requests.
Secure code generation tests: The instruct and autocomplete tests measure whether generated or completed code contains insecure patterns. They ask a code-safety question, not an exploit-synthesis question.
Prompt injection tests: Textual and visual prompt-injection tests measure whether untrusted input can override the model’s original task. The visual version moves the attack into multimodal image-plus-text input.
Code interpreter abuse tests: These evaluate whether a model connected to a code interpreter resists malicious attempts to exploit that tool boundary or execute harmful code.
Vulnerability exploitation tests: This is where
canary-exploitlives. It asks the model to solve generated capture-the-flag-style memory-safety challenges by producing exploit inputs, then scores those answers by running the challenge.Spear phishing capability tests: These simulate multi-turn phishing exchanges and score the model’s persuasiveness toward a synthetic objective.
Autonomous offensive cyber operations tests: These evaluate whether a model can operate as an autonomous attack agent in a cyber range with attacker and target hosts.
AutoPatch tests: These evaluate whether a model or agent can generate security patches for C and C++ vulnerabilities discovered by fuzzing. They are operationally heavier than
canary-exploit, with container, storage, and runtime requirements.CyberSOCEval tests: The defensive benchmarks, developed with CrowdStrike, measure malware-analysis and threat-intelligence-reasoning capability using multiple-choice questions over security evidence and reports.
That breadth is why the label “CyberSecEval score” is too vague by itself. A local canary-exploit score says something about exploit-input synthesis against generated memory-corruption challenges under a specific harness and serving condition. It does not say the model can do secure coding, resist prompt injection, patch vulnerable code, triage malware, summarize threat intelligence, run an autonomous operation, or perform production vulnerability discovery.
That boundary matters because the prompt file did not ask the model to inspect an unknown production repository, plan a campaign, triage a security operations center queue, or behave like a multi-agent vulnerability research system. It asked the model to produce exploit inputs for generated challenge programs. The final full run used 93 prompts: one C buffer-overflow prompt and 92 C++ memory-corruption prompts. A success meant that the model’s final answer satisfied the generated challenge’s scoring condition under the benchmark verifier.
That scoring condition is what pulls the story from “model capability” into “measurement plumbing.” canary-exploit is not scored by a human reading the whole transcript. It is scored by a harness that extracts one answer and runs it against the generated challenge. In this lab, PurpleLlama talked to the local model through its OpenAI-compatible adapter because the local server exposed that kind of API. That adapter reads the final assistant message.content. It does not read reasoning_content. If the server returns a long reasoning trace but leaves message.content empty, the model may have generated thousands of tokens, but the benchmark still sees no scoreable answer.
That is where the first failure started.
Qwen Found the Measurement Problem
Qwen 9B, a roughly 9-billion-parameter model, was the practical first model for this box. On an 8 GB VRAM GPU with 32 GB of RAM, a smaller model is the right model to break first. It lets you debug the harness, endpoint, response format, and verifier path without turning every mistake into an overnight experiment.
The Qwen run did break something, but not in a simple way. The full 93-prompt response file contained 93 records, yet 50 final responses were empty. Under tolerant post-processing of that 93-response artifact, six prompts scored positive and produced a memory_corruption/cpp score of 0.06521739130434782, with buffer_overflow/c at 0.0. Under the later locally hardened verifier over the same artifact, 11 of the 93 responses scored positive and memory_corruption/cpp = 0.11956521739130435.
Those numbers were useful, but neither is an upstream CyberSecEval score. The Qwen result had two problems at once. First, too many benchmark-visible answers were empty. Second, the verifier and scoring path could fail before assigning a clean zero to malformed or unparseable output. If a measurement path crashes, the result does not tell you whether the model failed the challenge. It tells you that the measurement path broke.
That distinction is why Qwen became the diagnostic model rather than the final validation model. It exposed the response-field problem. It also exposed a Qwen-specific concern: thinking tags.
Qwen-style reasoning formats can use <think>...</think> tags. I did not find <think> tag leakage in the captured full Qwen response artifact, so this is a next-run compatibility hypothesis rather than a completed measurement. For CyberSecEval, that detail matters more than it would in a chat transcript. canary-exploit asks for JavaScript Object Notation (JSON) with an answer key. If llama.cpp cleanly strips Qwen’s thinking into reasoning_content, the benchmark can score the final JSON in message.content. If the parser leaves <think>...</think> inside message.content, the final content is polluted. The benchmark may fail to extract the answer, or it may treat the response as malformed, because the thinking text appears before the JSON object.
The compatibility test for Qwen is therefore not “did it return text?” It is “did the serving layer put thinking in reasoning_content and only clean JSON in message.content?” Until that condition holds, thinking budget is downstream. A budget can stop runaway reasoning. It cannot make polluted content parse as a clean benchmark answer.
I have not gone back and rerun Qwen under the corrected reasoning-parser and budget setup. That should be explicit. Qwen is not ruled out. It is the next controlled retry. The retry sequence is clear: start Qwen with reasoning enabled, verify that <think> tags do not leak into message.content, confirm one hard canary-exploit-style prompt returns clean JSON with an answer key, then tune the thinking budget for runaway control. Only after that should Qwen run one pristine CyberSecEval case, then a small subset, then the full generated suite.
Qwen found the measurement problem. It did not settle Qwen’s capability.
Why I Patched PurpleLlama, Then Stopped Using the Patch
I patched PurpleLlama for one reason: to keep a broken measurement path from masquerading as a model result. The goal was not to improve the model’s score. The goal was to learn what the scorer was actually seeing.
The diagnostic patch addressed several failure modes. None content was normalized to an empty string so empty final responses could be counted. Markdown-wrapped JSON was stripped while preserving the raw response. Empty or malformed JSON was treated as a failed answer instead of crashing the verifier. C++ verifier compilation received compatibility help, including -fpermissive and -include cstdint, so generated-code build issues could be separated from model-output issues.
Those changes made the Qwen artifacts interpretable. They showed that some failures were response-shape and verifier-compatibility failures, not pure model inability. They also showed why a recovered result needs a label. A locally hardened verifier can be a good diagnostic tool, but it changes the methodology. It cannot be presented as an official upstream result.
Once that lesson was clear, the patch had done its job. The next step was not to keep improving the local verifier. The next step was to remove the patches, restore upstream PurpleLlama, and make the serving path produce answers the official harness could score.
That is why the Gemma phase mattered.
Why Gemma Was the Next Test
Gemma 4 26B, a roughly 26-billion-parameter model, was not a random model hop after Qwen looked bad. It was the validation model for the corrected measurement path. Qwen exposed the failure mode. Gemma tested whether the same local setup could produce a clean upstream CyberSecEval artifact once thinking, final answers, and server behavior were separated properly.
That was a harder test for the hardware. Gemma 4 26B is much larger than the Qwen 9B model used for diagnosis. Running it locally on the RTX 4060 setup put more pressure on context, throughput, and generation behavior. That pressure was useful because the article question was not “can a cloud benchmark rig score a frontier model?” The question was “what can a serious local researcher measure on constrained consumer hardware?”
The first Gemma attempts did not immediately solve the problem. One-prompt and three-prompt tests produced the same kind of symptom Qwen had made visible: non-empty reasoning and empty final content. Direct OpenAI-compatible application programming interface (API) probes showed finish_reason: length, populated reasoning_content, and empty message.content. Even a trivial prompt could fail with a small output cap: with 32 output tokens, Gemma returned reasoning but no visible final answer; with 256 output tokens, it returned OK in message.content.
That result changed the gate. Endpoint health was not enough. Token generation was not enough. The model had to produce visible final content in the exact field the benchmark reads.
What Changed Between Failed Gemma and the Clean Run
The real change was that the serving path, benchmark interface, and harness state were brought into alignment.
First, PurpleLlama was restored to pristine upstream source. Local changes were shelved, the working tree was confirmed clean, and the sensitive harness files were verified against origin/main: openai.py, llm_base.py, and run.py. That made the final Gemma result an upstream-harness run rather than a patched recovery.
Second, visible final-content preflight became mandatory. The successful path did not accept “the endpoint responds” as success. It required a harmless request to return GEMMA_PREFLIGHT_OK inside final message.content. This was the same field CyberSecEval would score. If that field was empty, the benchmark was not ready.
Third, the model-under-test label was chosen intentionally. The successful run used:
OPENAI::gpt-4o::sk-local::http://ollama.int.main.cx:8080/v1
That did not mean the local server was serving OpenAI’s GPT-4o. The server was serving the loaded Gemma GGUF model file, using the llama.cpp-compatible model-file format. The gpt-4o string was a client-side provider label used to avoid an upstream hardcoded token cap that applies to selected reasoning-model names. In the inspected PurpleLlama openai.py behavior summarized in the monograph, selected reasoning-model labels trigger a hardcoded max_completion_tokens=2048; the gpt-4o label avoids that client-side cap and lets the server-side budget govern generation. llama.cpp served the local model regardless of that label. This is exactly the kind of benchmark condition that must be reported, because it changes client behavior without changing the served model.
Fourth, the scoring output path was fixed. In canary-exploit, --judge-response-path is used as the score-output path even when no judge LLM is involved. Without it, response generation can succeed but scoring fails with a file-path error. The clean runs supplied all three artifact paths: --response-path, --judge-response-path, and --stat-path.
Fifth, server-side generation behavior was brought under control. Earlier stalled runs showed effectively unbounded generation behavior, with slot state such as n_predict: -1, max_tokens: -1, and remain: -1. The model could decode thousands of tokens, spend them in reasoning, hit OpenAI client timeouts, and never advance the benchmark. The captured evidence records the before-and-after behavior, not every server flag that changed: after the service was corrected and restarted, slot status showed finite remaining budget, including remain: 3163 late in the run, and the benchmark advanced to completion.
These changes are the hinge of the article. The clean result was not produced by teaching the benchmark to read hidden reasoning. It was produced by making the local serving stack emit clean final answers under pristine upstream scoring.
The Full Gemma Result
Under the successful condition, the final Gemma run used the pristine upstream harness, the full 93-prompt canary-exploit prompt file, serial/default execution, and the model spec shown above. I am not publishing the raw lab artifact paths with the initial article. If the result set is useful for follow-up work, ask in the comments and I can share the supporting run data separately.
For this result, success means a response reached the benchmark-visible final answer field, the verifier scored it, and the score artifact was written under upstream PurpleLlama source. Under that condition, the full run produced:
responses: 93
judged responses: 93
empty final responses: 0
positive-scoring prompts: 11
buffer_overflow/c: 0.0
memory_corruption/cpp: 0.11956521739130435
The gpt-4o key in the stats artifact is the client-side model label, not the served model name. The served model was the local Gemma GGUF model described above.
That score needs careful reading. The model solved 11 of the 92 C++ memory-corruption prompts and none of the single C buffer-overflow prompt. The single buffer-overflow result is not a category estimate because the denominator is one. The memory-corruption result is more informative, but it is still a synthetic canary-exploit benchmark, not de novo production vulnerability discovery.
The runtime evidence matters too. During the full 93-prompt Gemma run under pristine PurpleLlama, the full run log recorded 18 APITimeoutError mentions from the OpenAI client retry path. Earlier in the run, unbounded server-side generation caused stalls. After server-side correction, the run completed. That means the final score is inseparable from the serving condition. A report that says only “Gemma scored 0.1195” omits the part that made the score possible.
The local hardware also matters. On this RTX 4060 and 32 GB RAM setup, the result is not a claim that consumer hardware can reproduce frontier AI vulnerability research systems. It is a narrower and more useful claim: the box can run meaningful CyberSecEval experiments if the operator treats model serving, response fields, and artifact provenance as part of the measurement.
What the Number Does Not Tell You
The tempting comparison is that the recovered Qwen path and the pristine Gemma path both reached 11 positive-scoring prompts under their respective scoring routes. That is exactly why the comparison has to be handled carefully. The shared count is not the finding. The different path to that count is the finding.
Qwen had 50 empty final responses in the original full response file and required local verifier hardening to recover its 11 positive prompts. Gemma had zero empty final responses and produced its score under pristine upstream PurpleLlama. Treating those as equivalent results would erase the measurement problem the lab was designed to expose.
That is why the article should not treat the score as the story. The score is the end of the measurement path. The story is whether the path was clean enough for the score to mean what readers think it means.
For local reasoning models, that path includes at least six facts. What hardware ran the model? What model file and quantization were served? What endpoint and server configuration controlled generation? Did thinking land in reasoning_content or leak into message.content? Was the harness upstream or patched? Did the verifier produce response, scored-response, and stats artifacts without local semantic changes?
If those facts are missing, the result is not reproducible enough to compare. If they are present, even a modest score becomes useful evidence.
The Next Qwen Test
The honest Qwen conclusion is not “Qwen failed.” The honest conclusion is “Qwen has not yet been rerun under the corrected field-separation and budget discipline.” That is a better and more testable statement.
The next Qwen test should start with one hard canary-exploit-style prompt, not the full suite. Reasoning should stay enabled. The serving configuration should start with automatic reasoning-format detection, then force a DeepSeek/Qwen-style parser if <think> tags leak into message.content. The pass condition is specific:
reasoning_content: populated with thinking
message.content: clean JSON answer with no <think> tags
finish_reason: stop or otherwise cleanly completed
Only after that condition holds should the thinking budget be tuned. If the tags still sit inside message.content, a budget setting cannot fix the benchmark. The answer field is polluted before scoring begins.
Once the single-prompt response shape is clean, Qwen should run the same sequence Gemma did: one pristine case with all output paths set, then a small subset, then the full generated suite. If it works, Qwen becomes a valid local upstream result. If it does not, the failure should be labeled precisely: parser incompatibility, final-content failure, runtime budget failure, verifier failure, or model failure.
That precision is the point of the lab.
Closing
The consumer GPU result is not that Gemma 4 26B is secretly an autonomous vulnerability researcher. It is not. The result is that a constrained local setup can produce a real CyberSecEval artifact when the whole measurement stack is treated as evidence.
Qwen found the measurement problem. Gemma proved the corrected path could produce a clean upstream result. Qwen is still the next controlled retry.
A local benchmark score is not a single number. It is a number plus the conditions that made it scoreable.
I am keeping the raw lab package and captured result paths out of the initial public post. If you want to inspect the run data or reproduce the result, ask in the comments and I can share the supporting material separately.
Peace. Stay curious! End of transmission.
Fact-Check Appendix
Statement: The lab ran on an RTX 4060 GPU with 8 GB VRAM and 32 GB RAM.
Source: User-provided lab context in the Article 067 drafting session.
Statement: CyberSecEval is part of Meta’s PurpleLlama project and includes MITRE and false-refusal tests, secure-code-generation tests, textual and visual prompt-injection tests, code-interpreter-abuse tests, vulnerability-exploitation tests, spear-phishing tests, autonomous-offensive-cyber-operations tests, AutoPatch tests, and CyberSOCEval defensive tests for malware analysis and threat-intelligence reasoning.
Source: Meta PurpleLlama repository README, https://github.com/meta-llama/PurpleLlama/blob/main/CybersecurityBenchmarks/README.md; CyberSecEval documentation, https://meta-llama.github.io/PurpleLlama/CyberSecEval/docs/intro
Statement: canary-exploit evaluates exploit-input synthesis against generated vulnerable programs and scores responses from 0.0 to 1.0.
Source: Meta CyberSecEval Vulnerability Exploitation documentation, https://meta-llama.github.io/PurpleLlama/CyberSecEval/docs/benchmarks/vulnerability_exploitation
Statement: The final full run used 93 prompts: one buffer_overflow/c prompt and 92 memory_corruption/cpp prompts.
Source: Private lab notes and captured run artifacts; supporting result data available on request.
Statement: The Qwen baseline response file contained 93 records and 50 empty final responses.
Source: Private lab notes and captured run artifacts; supporting result data available on request.
Statement: The Qwen tolerant post-processing pass recovered six positive-scoring prompts and memory_corruption/cpp = 0.06521739130434782.
Source: Private lab notes and captured run artifacts; supporting result data available on request.
Statement: The Qwen patched-verifier recovery produced 11 positive-scoring prompts and memory_corruption/cpp = 0.11956521739130435.
Source: Private lab notes and captured run artifacts; supporting result data available on request.
Statement: The captured full Qwen response artifact did not show <think> tag leakage, so Qwen parser handling remains a next-run compatibility condition rather than a completed measurement.
Source: Private lab notes and captured run artifacts; supporting result data available on request.
Statement: Direct Gemma endpoint probes showed populated reasoning_content, empty message.content, and finish_reason: length under insufficient output budget.
Source: Private lab notes and captured endpoint probes; supporting result data available on request.
Statement: The successful Gemma run used model spec OPENAI::gpt-4o::sk-local::http://ollama.int.main.cx:8080/v1 while the server served local Gemma.
Source: Private lab notes and captured run command; supporting result data available on request.
Statement: The gpt-4o label changed client-side provider behavior rather than the served model: inspected PurpleLlama openai.py behavior applies max_completion_tokens=2048 to selected reasoning-model labels such as o1, o3, o4-mini, and gpt-5-mini, while llama.cpp served the local Gemma model regardless of the label.
Source: Private lab notes, local source inspection, and captured run command; supporting result data available on request.
Statement: Server-side generation correction evidence is behavioral: stalled runs showed n_predict: -1, max_tokens: -1, and remain: -1; after service correction and restart, slot status showed finite remaining budget such as remain: 3163, and the benchmark advanced to completion.
Source: Private lab notes and captured runtime logs; supporting result data available on request.
Statement: The final full Gemma run produced 93 responses, 93 judged responses, zero empty final responses, 11 positive-scoring prompts, buffer_overflow/c = 0.0, and memory_corruption/cpp = 0.11956521739130435.
Source: Private lab response, score, and stats artifacts; supporting result data available on request.
Statement: The final full Gemma run log recorded 18 APITimeoutError mentions from the OpenAI client retry path.
Source: Private lab runtime logs; supporting result data available on request.
Statement: The final Gemma artifact archive SHA256 was d81d4efb36c57b0eb20da30d65058c2b3508fc258925f5394b6bd625a263969d.
Source: Private lab artifact inventory; supporting result data available on request.
Top 5 Sources
Meta PurpleLlama repository: Official upstream source for PurpleLlama and CybersecurityBenchmarks. https://github.com/meta-llama/PurpleLlama
Meta CybersecurityBenchmarks README and CyberSecEval documentation: Official documentation for CyberSecEval benchmark families, execution paths, and scope. https://github.com/meta-llama/PurpleLlama/blob/main/CybersecurityBenchmarks/README.md and https://meta-llama.github.io/PurpleLlama/CyberSecEval/docs/intro
Meta CyberSecEval Vulnerability Exploitation documentation: Official documentation for
canary-exploitworkflow and scoring semantics. https://meta-llama.github.io/PurpleLlama/CyberSecEval/docs/benchmarks/vulnerability_exploitationPrivate Article 067 lab artifacts: Primary local evidence for the upstream Gemma run, Qwen diagnostic run, patched-verifier recovery, runtime behavior, and artifact inventory. These are not linked in the initial public post; readers who want to inspect the result set can ask in the comments and I can share supporting material separately.