
ESCAPING THE BLACK BOX: The Architecture of Glass Citadel and the Rise of Sovereign AI
Glass Citadel is a blueprint for Sovereign AI: a robust, self-correcting RAG architecture that replaces black-box APIs with controllable, OSS infrastructure, optimizing for ownership and debuggability

DISCLAIMER: A Reference Architecture, Not a Production System
Glass Citadel is an architectural blueprint designed to demonstrate the concepts of Sovereign AI, Agentic RAG, and Model Arbitrage. It is a Proof of Concept (PoC) intended for educational and prototyping purposes.
It is NOT ready for production deployment. Critical features required for a real-world enterprise environment are intentionally omitted to keep the code readable and focused on the core logic:
Security: There is no user authentication (Auth0/OAuth), Role-Based Access Control (RBAC), or robust input sanitization.
Infrastructure: It runs on Docker Compose (single node), lacking the redundancy, scaling, and orchestration (Kubernetes) needed for high availability.
User Experience: The chat interface is built with Streamlit—excellent for rapid prototyping, but insufficient for a responsive, consumer-facing application.
Resilience: While it includes basic retries, it lacks industrial-grade error handling, circuit breakers, and comprehensive integration testing.
Treat this code as a laboratory workbench to experiment with the architecture of thought, not a fortress ready to hold customer data as is.
TL:DR;
Most AI tutorials today teach you to build “Smart Parrots”—brittle scripts that feed data into a black-box API and hope for the best. They work for a single PDF but crumble under real-world complexity, confusion, and the crippling “Economic Bleed” of using massive models for trivial tasks.
Glass Citadel is the antidote. It is a reference architecture for Sovereign AI: a system where you own the infrastructure, control the data, and orchestrate intelligence like a supply chain. We move beyond simple RAG to a robust, self-correcting agentic workflow powered by four open-source pillars: Qdrant for hybrid memory, Phoenix Arize for “X-Ray” observability, LiteLLM for model arbitrage, and Docling for industrial-grade ingestion.
This article breaks down how to build a “Two-Brain” system that splits cognition into cost-effective Orchestration and eloquent Generation. We detail the “Gap-Filling” planner that hunts for missing data, the “Doubly-Linked List” retrieval that never loses context, and the transparent UI that builds user trust. Stop building fragile scripts. Start building a fortress of reasoning that you actually own.
Oh, the TL:DR; also needs the link for those of you that are overly anxious to check the code and get your hands dirty!
Feel free to fork and submit PR’s.
THE PROBLEM: The “Smart Parrot” and the Integration Trap
We are living in the “Hello World” era of Artificial Intelligence. If you open YouTube or GitHub today, you will find ten thousand tutorials on how to build a “Chat with your PDF” application. They all look the same: a Python script that uploads a file, splits it into arbitrary chunks, sends it to OpenAI, and hopes for the best.
We call this the “Smart Parrot” architecture.
It works beautifully for a single document. You ask, “What is the summary?” and the parrot squawks back a perfect summary. But the moment you try to scale this—the moment you feed it 5,000 financial reports, 10 years of legal history, or the entire technical documentation of a battleship—the parrot dies.
It confuses the 2023 Risk Factors with the 2024 Risk Factors. It hallucinates connections between two companies that simply do not exist. It crashes when the internet flickers.
Furthermore, it suffers from The Economic Bleed. Most “Smart Parrots” use a single, massive model (like GPT-4) for every single step of the process. They use a Ferrari to drive to the mailbox. Using a $20/million-token model to extract a simple date from a string or to decide if a document is relevant is not just inefficient; it is financial negligence.
Most critically, it is a “Black Box.” You feed data into a proprietary API, and you get an answer back, but you have zero visibility into why that answer was chosen.
This is the Integration Trap. We have become experts at glueing together APIs we don’t understand to build systems we can’t debug.
Glass Citadel does not escape this trap entirely—it still requires understanding Qdrant, Phoenix, and LiteLLM. But it reframes the trap: instead of depending on opaque proprietary APIs, we depend on open-source tools with visible internals, local deployment options, and standardized interfaces. The trap becomes a toolkit.
Glass Citadel is the rejection of that fragility. It is an architectural blueprint for Sovereign AI—systems that run on your infrastructure, reason over your private data, and explain their thinking step-by-step. It is not a script; it is a system.
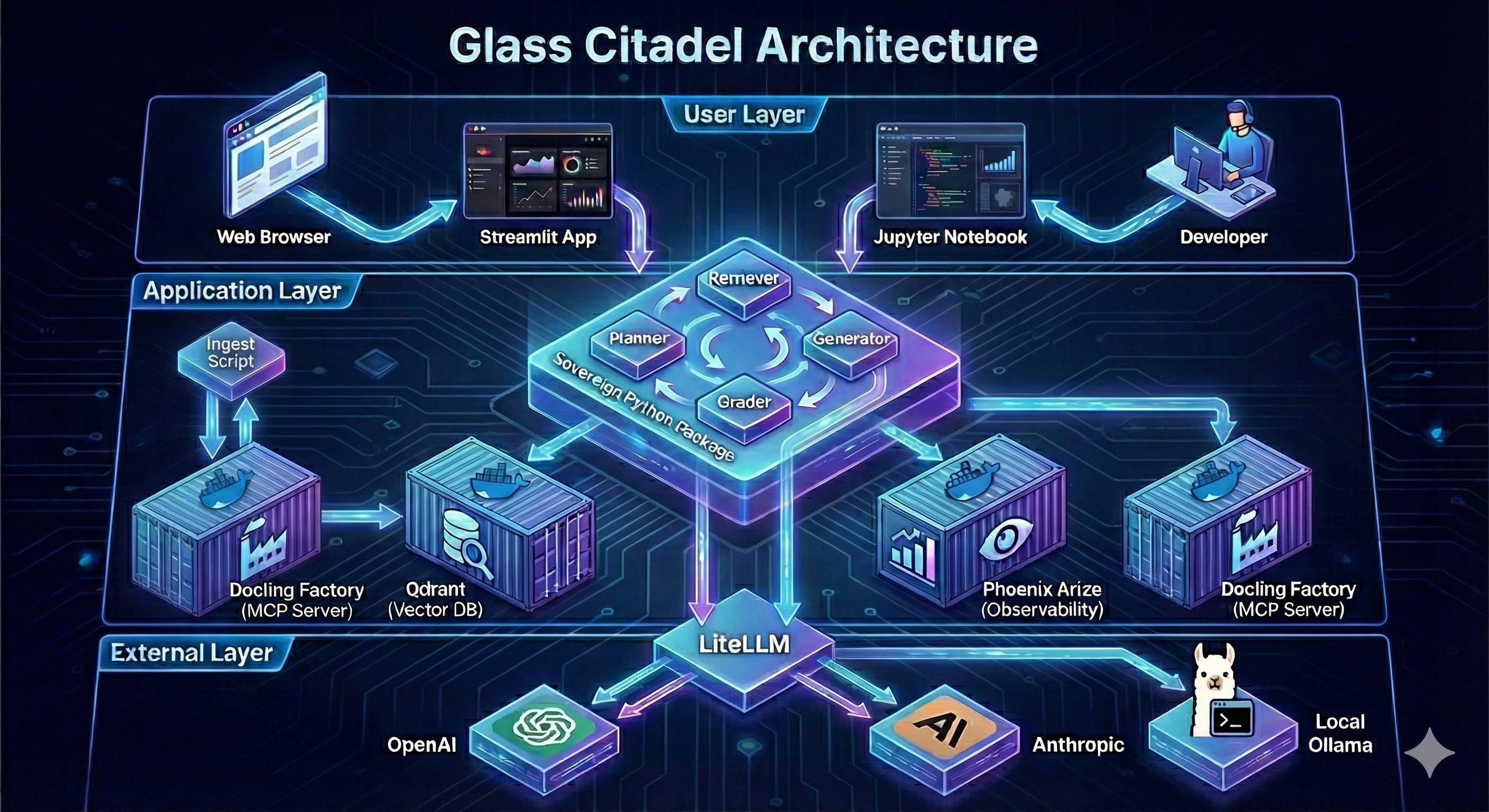
THE INFRASTRUCTURE: The 4 Pillars of Sovereignty
Before we look at the Python code, we must understand the physical layout of the Citadel. It is not a monolith. It is a distributed system built on four open-source pillars, orchestrating distinct responsibilities: Memory, Vision, Translation, and Ingestion.
1. Qdrant (The Memory)
In the “Smart Parrot” world, memory is a simple list of numbers. In Glass Citadel, memory is a high-performance search engine. We use Qdrant, a vector database written in Rust. It handles the heavy lifting of storing millions of embeddings and performing “Hybrid Search”—simultaneously matching semantic meaning (Dense Vectors) and exact keywords (Sparse Vectors). It is the hippocampus of our system.
2. Phoenix Arize (The Eyes)
How do you debug a thought? If your AI makes a mistake, you cannot “step through” it with a traditional debugger because the logic is probabilistic. We use Phoenix Arize for LLM Observability. It acts as an “X-Ray” machine, capturing every step of the agent’s execution (the Plan, the Filter, the Retrieval, the Grade) via the OpenTelemetry standard (an open-source standard for instrumenting software to generate telemetry data like traces, metrics, and logs). This allows us to visualize the “Trace” of a thought process and pinpoint exactly where the hallucination occurred.
3. LiteLLM (The Universal Translator & Gateway)
Vendor lock-in is the silent killer of AI projects. If you hardcode openai.ChatCompletion throughout your codebase, you are effectively owned by OpenAI. When they change their pricing, deprecate a model, or suffer an outage, your Citadel falls.
Glass Citadel uses LiteLLM as a strategic decoupling layer. It functions as a universal translator that normalizes inputs and outputs across 100+ providers—Anthropic, Azure, AWS Bedrock, Google Vertex, and even local models via Ollama or vLLM.
The Mechanism of Sovereignty: LiteLLM exposes a standardized, OpenAI-compatible API. This means our agent code thinks it is talking to GPT-4, but in reality, it might be communicating with:
Claude 3.5 Sonnet for complex reasoning.
DeepSeek R1 running on a private server for cost efficiency.
Llama 3 running locally on your laptop for offline privacy.
By simply changing a single environment variable (PROXY_GENERATION_MODEL_ID), we can swap the entire brain of the system instantly. This enables Model Arbitrage—routing traffic to the cheapest capable model—and ensures our architecture is anti-fragile, capable of surviving any single provider’s failure.
4. Docling & MCP (The Hands)
Reading files is surprisingly hard. PDFs are a chaotic mess of floating text boxes. We use Docling, a specialized IBM research model running in a Docker container, to perform “Layout-Aware” parsing. It understands that a table is a table, not a soup of words. We wrap this in the Model Context Protocol (MCP) (a standardized way for AIs to interact with external tools), a new standard that lets our AI “call” the document parser as a tool, decoupling the heavy processing from the lightweight reasoning agent.
THE ECONOMICS OF INTELLIGENCE: LLMOps & Model Arbitrage
In traditional software, compute costs are relatively flat. In AI, they are volatile. Glass Citadel treats intelligence not as a magical monolith, but as a commoditized supply chain. This allows us to practice Model Arbitrage: the strategic routing of tasks to the most efficient model capable of solving them.
The “Two-Brain” Strategy
A complex RAG system has two distinct types of cognitive load:
Orchestration (High Input / Low Output): Reading 50 pages of documents to extract three dates, or deciding if a paragraph is relevant. This requires high reading speed and strict JSON adherence, but very little “creative” intelligence.
Generation (Low Input / High Output): Synthesizing the final answer into eloquent, nuanced prose. This requires high reasoning capabilities and world knowledge.
Glass Citadel splits these functions. We use an Orchestration Model (e.g., gpt-4o-mini, claude-haiku, or a localized llama-3-8b) for the heavy lifting of planning and filtering. We reserve the expensive Generation Model (e.g., gpt-4o, claude-3.5-sonnet) only for the final mile.
Metrics That Matter: Beyond Just Tokens
By decoupling these roles, we optimize for:
Input vs. Output Costs: Orchestration is 90% reading (Input). Since input tokens are often 1/10th the price of output tokens, we route this bulk reading to models that specialize in massive context windows at low cost.
Latency & Tokens/Watt: When running locally, a small 8B parameter model might run at 100 tokens/second on a consumer GPU, consuming 200 Watts. A 70B model might run at 15 tokens/second consuming the same power. For the “Grader” node, which runs hundreds of times, the smaller model is objectively superior—not just cheaper, but faster and greener.
Cost of Correction (Retry Rate): A seemingly “cheap” model is only cheap if it gets the job done correctly on the first try. If an orchestration model fails to produce valid JSON or makes poor planning decisions, leading to multiple retries (which
Glass Citadel‘srevision_counttracks), the cumulative cost and latency can quickly surpass that of a more expensive, but more reliable, model. Optimizing for success rate, not just unit token cost, is paramount.Context Caching Efficiency (Future Enhancement): While not implemented in this reference architecture, production deployments should consider this optimization. In multi-turn conversations or iterative analysis, much of the contextual information (system prompts, retrieved documents) remains constant. Advanced LLM providers and inference servers (e.g., LiteLLM gateways, local vLLM instances) can “cache” this prefix, only charging or processing the new user input. This dramatically reduces input token costs and latency for subsequent turns.
(Note: The current Glass Citadel reference implementation does not explicitly enable caching. Doing so in a truly provider-agnostic way would require significant complexity, as each provider (e.g., Anthropic, DeepSeek) requires different API headers or specific prompt formatting to trigger their cache. We chose to keep the codebase clean, but in a production deployment, you would wrap the
completioncall with logic to inject these provider-specific signals.)
This is the essence of Sovereign AI: You are not just a user of models; you are a manager of a cognitive workforce.
A Worked Example (Coming Soon)
The claims made above regarding cost, latency, and efficiency are not theoretical. In a forthcoming article, I will provide a detailed, worked economic analysis of a real-world multi-model agentic system. This will include concrete data on token usage, model performance, and actual dollar costs for different orchestration and generation model combinations, illustrating the tangible benefits of Model Arbitrage and the Two-Brain strategy. Stay tuned for a deep dive into the numbers. (Spoiler: This will be the next article I’ll publish)
With the economic rationale established, we can now translate these principles into running infrastructure. The Citadel is deployed across two Docker Compose stacks, each optimized for its cognitive role.
THE DEPLOYMENT: Spinning Up the Citadel
Code is useless if it cannot run. To deploy the Citadel, we separate concerns into two distinct “Zones,” managed by Docker Compose. This ensures that your heavy GPU ingestion tasks (The Factory) do not starve your latency-sensitive query engine (The Brain).
Zone A: The Brain (Memory & Observability)
This stack runs the persistent infrastructure. It includes Qdrant for storage and Phoenix for monitoring. It is lightweight and meant to run 24/7.
infra/brain/docker-compose.yml
services:
# 1. THE MEMORY (Qdrant)
# Stores vectors with Hybrid Search (Dense + Sparse)
qdrant:
image: qdrant/qdrant:latest
container_name: sovereign_memory
restart: always
ports:
- “6333:6333” # REST API (a standard for web service communication)
- “6334:6334” # gRPC (a high-performance remote procedure call framework)
volumes:
- ./qdrant_data:/qdrant/storage
environment:
- QDRANT__SERVICE__ENABLE_GRPC=true
# 2. THE EYES (Arize Phoenix)
# Captures traces from LangGraph to visualize “Reasoning”
phoenix:
image: arizephoenix/phoenix:latest
container_name: sovereign_eyes
restart: always
ports:
- “6006:6006” # UI
- “4317:4317” # OTLP gRPC (OpenTelemetry Protocol using gRPC for traces)
- “6007:6007” # OTLP HTTP (OpenTelemetry Protocol using HTTP for traces)
Zone B: The Factory (Ingestion)
This stack runs the heavy lifting. It contains the Docling MCP server. It is often deployed on a separate machine with a GPU (e.g., an NVIDIA A10 or T4) to accelerate OCR and PDF rendering.
infra/factory/docker-compose.yml
services:
docling-factory:
build: .
container_name: sovereign_factory
restart: always
ports:
- “8088:8088” # The MCP SSE Endpoint
volumes:
# Mount the Data Lake so the Factory can read local files
- ./data_lake:/app/data_lake
environment:
- OMP_NUM_THREADS=4 # Limit CPU threads if needed
# Uncomment below to enable GPU support (requires NVIDIA Container Toolkit)
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
THE SOLUTION: Inside the Application Logic
With the infrastructure running, we can now look at the software architecture that lives on top of it.
1. The Factory: Industrializing Ingestion via SSE and MCP
In standard RAG pipelines, “Ingestion” is often just a Python function that uses PyPDF2. It is brittle and slow. In Glass Citadel, we treat ingestion as a remote procedure call to a dedicated industrial facility.
We implemented the Model Context Protocol (MCP) (a standardized way for AIs to interact with external tools) over Server-Sent Events (SSE) (a browser API for receiving server updates over an HTTP connection). This is a sophisticated way of saying that our ingestion script acts as a client that “calls” the Factory over HTTP, but with a standardized schema for tools and resources.
The Protocol Flow:
Client (Ingest.py): Reads a local PDF file (binary).
Encoding: Base64 encodes the file content so it can travel safely over JSON-RPC.
Transmission: The client connects to
http://localhost:8088/sseand invokes the toolconvert_uploaded_file.Server (Server.py): The Factory receives the blob, decodes it, and saves it to an internal “Landing Zone.”
Processing: It triggers
docling.DocumentConverterto optically analyze the layout. It caches the result using a SHA-256 hash to avoid re-processing the same file twice.Return: The clean Markdown text flows back to the client.
infra/factory/server.py
@mcp.tool()
def convert_uploaded_file(filename: str, base64_content: str) -> str:
“”“
Accepts a file upload (Base64), saves it, and converts it to Markdown.
Handles caching automatically.
“”“
try:
# 1. DECODE & SAVE
target_path = INTERNAL_LAKE / filename
target_path.parent.mkdir(parents=True, exist_ok=True)
file_data = base64.b64decode(base64_content)
target_path.write_bytes(file_data)
print(f”📥 Received Upload: {filename} ({len(file_data)} bytes)”)
# 2. RUN STANDARD CONVERSION LOGIC
return _process_local_file(target_path)
except Exception as e:
return f”Error processing upload: {str(e)}”
This architecture allows the Factory to be hosted anywhere—on a local machine, a dedicated GPU server, or a cloud instance—without changing a single line of the client code.
2. The Brain: Logic Separated from the Body
The single most common mistake in AI engineering is coupling the logic to the view. You see this constantly: Streamlit apps where the prompt engineering, the vector search, and the LLM calls are all mixed into the main() function of the UI. This makes testing impossible. How do you test your prompt logic? You have to click buttons in the UI manually.
Glass Citadel solves this by abstracting the entire cognitive architecture into a dedicated Python package named sovereign.
The Package: Contains the
SovereignAgent, theGraphdefinition, and the State management.The Consumers: Both the Streamlit Web App (
app.py) and the Jupyter Notebook (sovereign_brain.ipynb) import this exact same package.
The Rapid Development Cycle: This architecture unlocks a powerful workflow for testing and iteration:
Experiment in the Notebook: We use
sovereign_brain.ipynbto tweak the agent’s logic. Because notebooks allow us to inspect variables, visualize search results, and replay specific graph nodes without reloading the entire environment, we can iterate 10x faster than rerunning a web server.Verify the Logic: Once the agent behaves correctly in the notebook (e.g., correctly extracting “Nvidia 2024”), the code is already saved in the
sovereign/package.Deploy to UI: We simply restart the Streamlit app. Since
app.pyimports the exact same class (SovereignAgent), the web interface inherits the new intelligence immediately.
app.py
from sovereign.agent import SovereignAgent, setup_observability
3. The Brain: Architecting the Agent
The core of Sovereign AI is not a single prompt; it is a Cognitive Architecture. We use LangGraph (a library for building stateful, multi-actor applications with LLMs) to define a state machine that enforces a specific “workflow of thought.”
The SovereignAgent class in sovereign/agent.py orchestrates this via a graph.
The Workflow Graph: The agent follows a strict path:
Planner: Deconstructs the user’s vague request into concrete search queries.
Filter Builder: Extracts entities (like “NVDA” or “2024”) to apply strict metadata filters.
Retriever: Executes the Hybrid Search against Qdrant.
Grader: Crucially, the agent evaluates its own work. It reads the retrieved documents and asks, “Is this sufficient?”
Loop or Act:
If Sufficient: Proceed to generate the answer.
If Partial: Loop back to the Planner to fill specific gaps (”Missing: EBITDA”).
If Irrelevant: Loop back to the Planner with feedback (”Try broader keywords”).
sovereign/agent.py (Workflow Definition)
def _build_workflow(self):
workflow = StateGraph(AgentState)
workflow.add_node(”planner”, self.planner_node)
workflow.add_node(”filter_builder”, self.filter_builder_node)
workflow.add_node(”retriever”, self.retriever_node)
workflow.add_node(”grader”, self.grader_node)
workflow.add_node(”generator”, self.generator_node)
workflow.set_entry_point(”planner”)
workflow.add_edge(”planner”, “filter_builder”)
workflow.add_edge(”filter_builder”, “retriever”)
workflow.add_edge(”retriever”, “grader”)
workflow.add_conditional_edges(
“grader”,
self.decide_to_generate,
{
“planner”: “planner”, # The “Self-Correction” & “Gap Filling” Loop
“generator”: “generator”
}
)
workflow.add_edge(”generator”, END)
return workflow.compile()
The Two-Brain System: We separate the cognitive load into two distinct models. The Orchestration Model (orchestration_model_id) handles the internal logic (Planner, Filter, Grader) where speed and structure are paramount. The Generation Model (generation_model_id) is reserved for the final synthesis, where nuance and eloquence matter most. This allows us to use smaller, faster models for the loop and larger, smarter models for the answer.
The Gap-Filling Planner: The planner_node is aware of failure. If it is called with missing_info in the state, it dynamically instructs the model to hunt for exactly what is missing.
sovereign/agent.py (Planner Logic)
def planner_node(self, state: AgentState):
# ...
missing = state.get(”missing_info”)
if missing:
system_prompt += f”\nNOTE: We found some initial data, but are missing: ‘{missing}’. Generate targeted queries to find EXACTLY this missing information.”
elif is_retry:
system_prompt += “\nNOTE: Previous searches failed to find relevant data. Try BROADER or DIFFERENT keywords.”
response = completion(
model=self.orchestration_model_id, # Uses the faster model
# ...
)
4. Precision Search: Linked Lists & Hybrid Vectors
Once the Markdown arrives back from the Factory, the real work begins. We don’t just “chunk” the text; we enrich it.
Step A: Contextual Splitting We use a MarkdownHeaderTextSplitter to split text based on headings, preserving the document’s skeleton.
Step B: The Doubly-Linked List (Infinite Context) A common failure in RAG is losing the narrative thread. To fix this, Glass Citadel implements a Doubly-Linked List structure within the vector database.
We generate deterministic UUIDs (
uuid5) for every chunk.We inject
prev_uuidandnext_uuidpointers into every chunk’s metadata.We also keep a “sliding window” of text (
prev_context/next_context) for instant access.
During retrieval, the agent fetches the top matches, then performs a batch fetch of all neighbor UUIDs. This stitches the document back together on the fly: [Prev Chunk] + [Match] + [Next Chunk]. This means the agent can effectively read “beyond the edges” of the retrieved segment.
ingestion/ingest.py
# Generate deterministic UUIDs for linking
chunk_uuids = [str(uuid.uuid5(uuid.NAMESPACE_DNS, f”{company}_{year}_{filename}_{i}”)) for i in range(len(docs))]
for i, doc in enumerate(docs):
# ... sliding window logic ...
payload = doc.metadata.copy()
payload.update({
“text”: chunks_text[i],
“prev_uuid”: chunk_uuids[i-1] if i > 0 else None,
“next_uuid”: chunk_uuids[i+1] if i < len(chunks_text) - 1 else None,
“chunk_index”: i,
# ... other metadata ...
})
Step C: Hybrid Vector Generation Finally, we generate two vectors for every chunk:
Dense Vector (bge-small-en-v1.5): Captures the meaning (e.g., “money made” matches “Revenue”).
Sparse Vector (Splade-PP): Captures the keywords (e.g., “EBITDA”, “Model X100”).
5. The Interface: Watching the Thought Process
Finally, the agent.py logic implements a Plan-Route-Act workflow. The Streamlit interface exposes this loop, showing the user exactly how the agent plans its search, filters by metadata, and grades its own results.
In Glass Citadel, we leverage Streamlit’s capabilities to stream the agent’s internal monologue in real-time. With DEBUG_MODE enabled, developers can even see the raw JSON queries sent to Qdrant. The user observes:
“Refining search strategy... (Attempt 2)”
“⚠️ Partial Match: Missing EBITDA. Refining Search...”
“Found 12 documents for ‘Nvidia 2024 Risk’...”
“✅ Sufficient Information Found”
This transparency builds trust. When a user sees the AI try a search, realize it’s missing data, and self-correct, they understand that the system is working hard, not hallucinating.
6. Introspection: The X-Ray of the Mind
Even with a transparent UI, developers need deeper insights. Why did the Planner choose those keywords? Why did the Grader reject that document?
We use Arize Phoenix to provide an “X-Ray” view of the agent’s cognition. By instrumenting our code with OpenTelemetry, every step of the LangGraph execution—from prompt formulation to LLM response—is traced and sent to the Phoenix server.
This allows us to:
Visualize the Graph: See the exact path the agent took (e.g., Planner -> Filter -> Retriever -> Grader -> Planner -> ...).
Inspect Latency: Identify which step (Retrieval vs. Generation) is slowing down the response.
Debug Prompts: Click on any node to see the exact input prompt sent to the LLM and the raw JSON output it returned.
We enable this with a single function call that auto-instruments the entire LangChain/LangGraph stack:
sovereign/agent.py
def setup_observability():
“”“
Initializes Phoenix/OpenTelemetry observability if PHOENIX_ENDPOINT is set.
Must be called AFTER environment variables are loaded.
“”“
try:
from openinference.instrumentation.langchain import LangChainInstrumentor
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
# ... imports ...
PHOENIX_ENDPOINT = os.getenv(”PHOENIX_ENDPOINT”)
if PHOENIX_ENDPOINT:
resource = Resource.create({”service.name”: “sovereign-rag-agent”})
tracer_provider = TracerProvider(resource=resource)
otlp_exporter = OTLPSpanExporter(endpoint=PHOENIX_ENDPOINT)
tracer_provider.add_span_processor(BatchSpanProcessor(otlp_exporter))
trace.set_tracer_provider(tracer_provider)
# Auto-instrument LangChain
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
print(f”✅ Phoenix observability enabled: {PHOENIX_ENDPOINT}”)
VISUALIZING THE CITADEL
To truly understand the system, it helps to see it in action across its three primary interfaces.
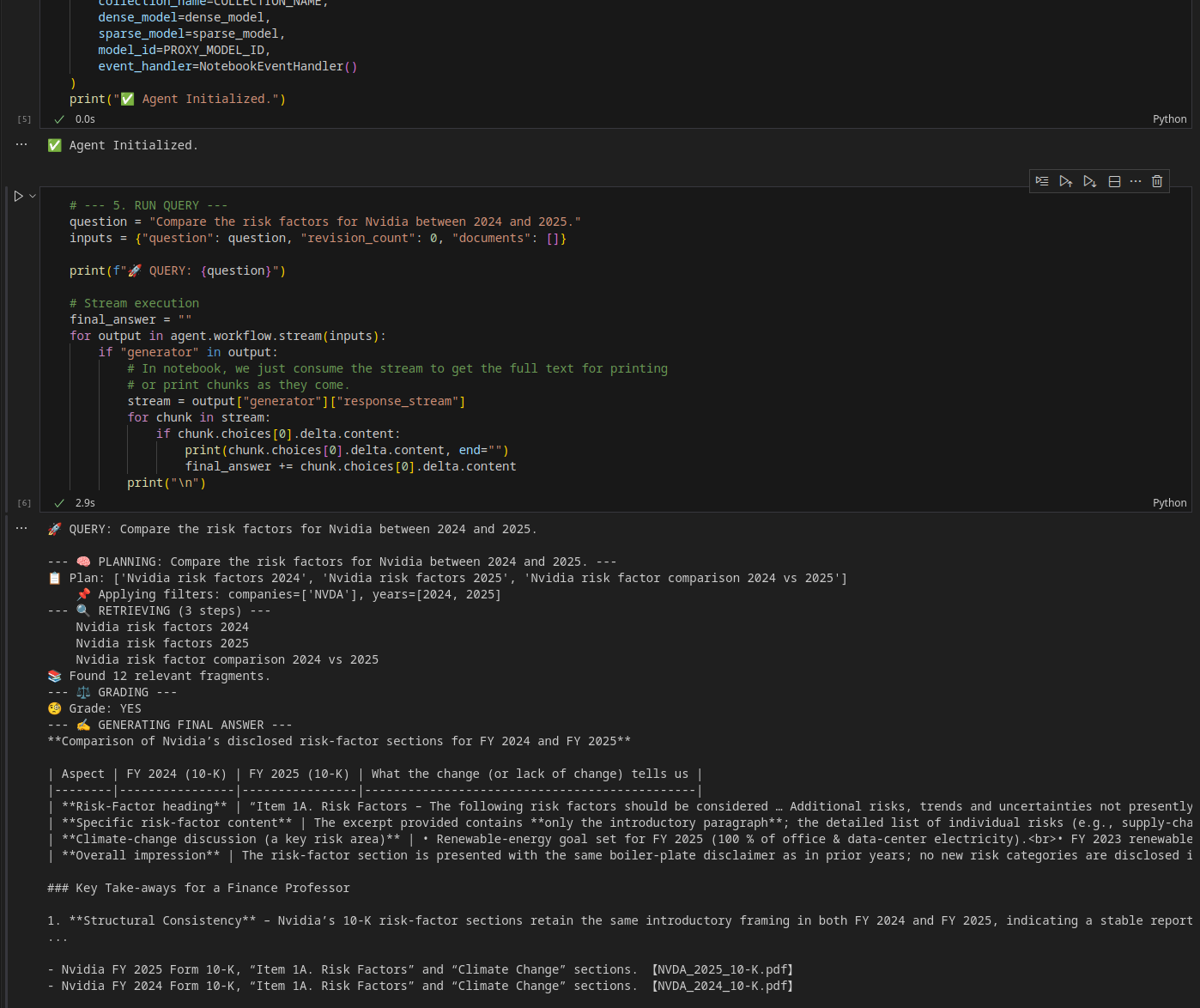
1. The Workbench (Jupyter Notebook)
This is where the logic is born. The notebook view shows the raw outputs of the planner and retriever, allowing for granular inspection of the data before it ever reaches the UI.
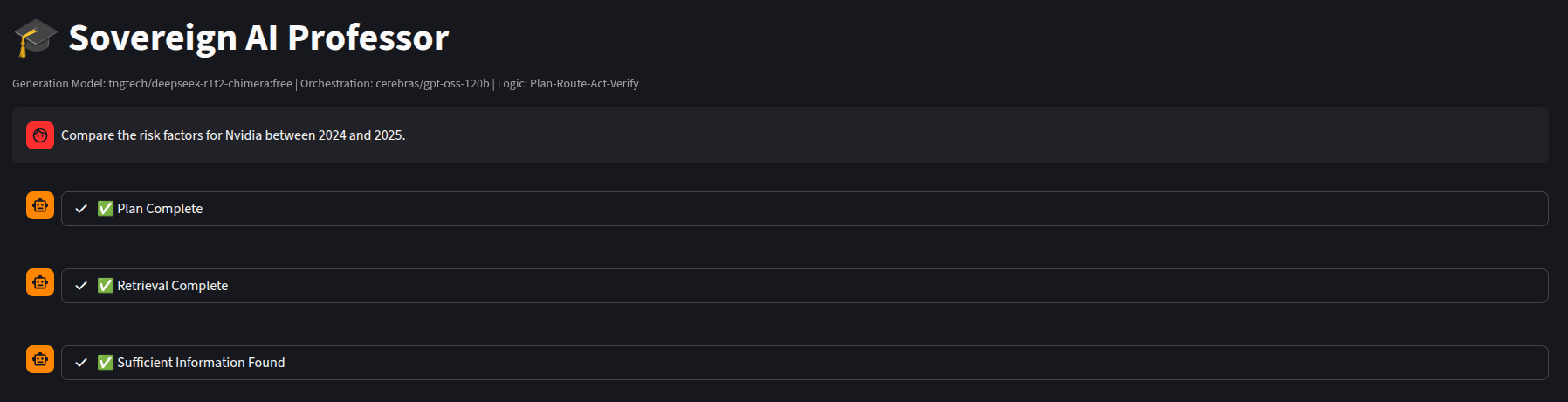
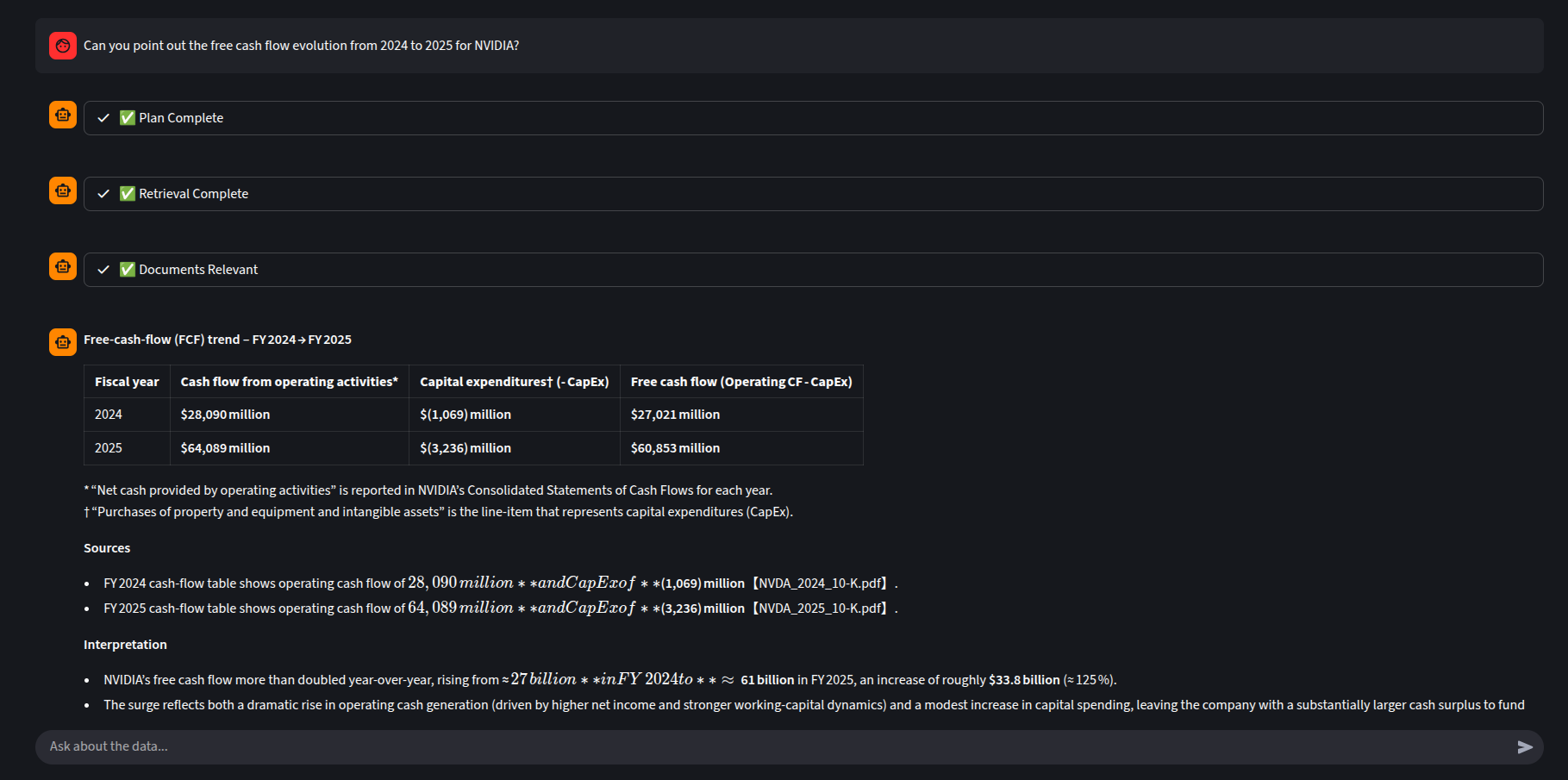
2. The Control Room (Streamlit App)
This is the user-facing “Sovereign Professor.” Notice the Plan, retrieval and relevancy test and the main chat interface streaming the thought process.
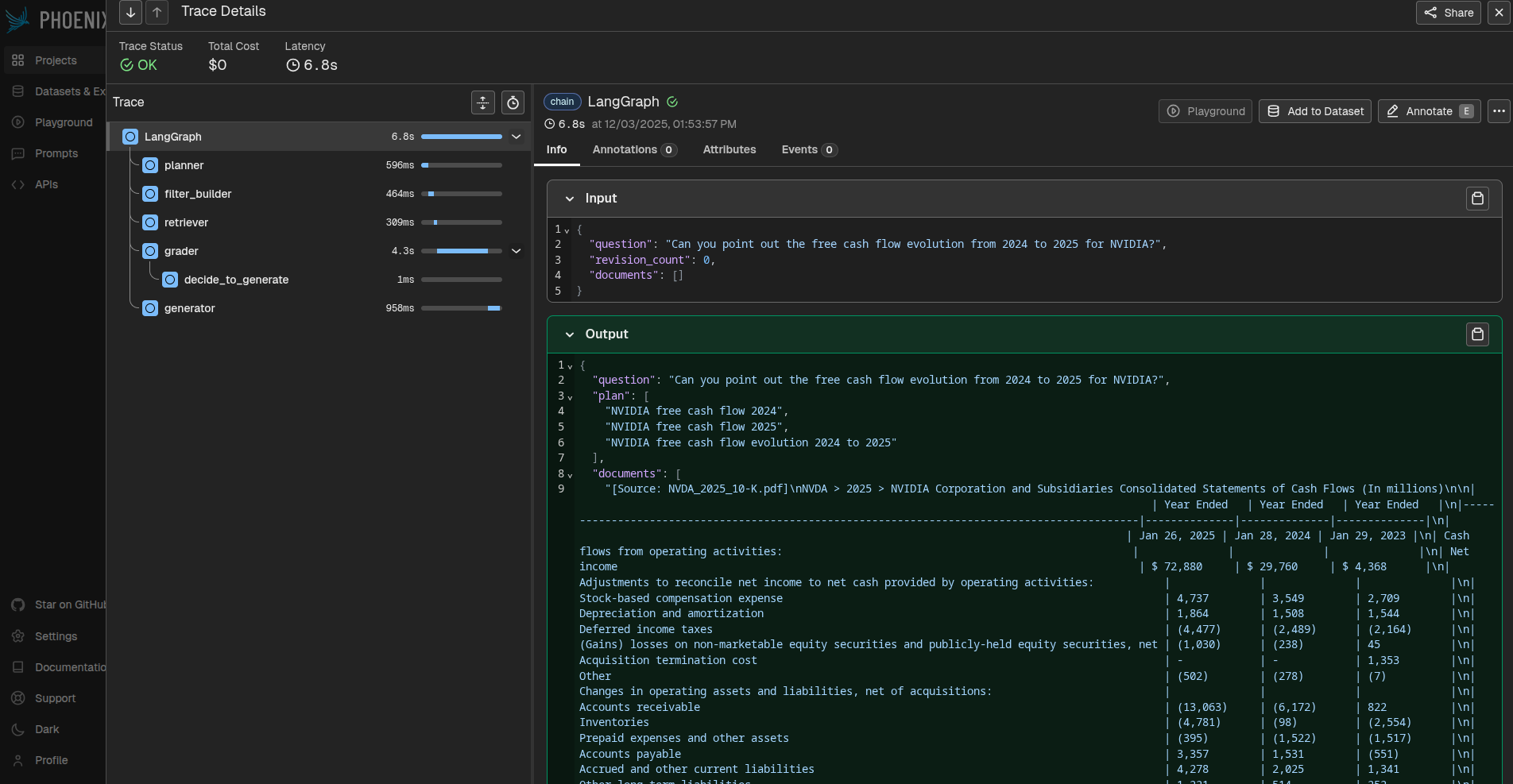
3. The X-Ray (Arize Phoenix)
This is the view for the engineer. It visualizes the LangGraph execution trace, showing the latency of each node (Planner, Retriever, Grader) and the exact prompts sent to the LLM.

THE ROADMAP: From Blueprint to Fortress
Glass Citadel provides a robust architectural blueprint for Sovereign AI, but it is explicitly a Proof of Concept. To transition this blueprint into a production-ready fortress capable of handling real-world enterprise demands, your team would need to implement several critical enhancements:
Authentication & Authorization: Integrate an authentication layer (e.g., OAuth/OIDC) to verify user identities and implement Role-Based Access Control (RBAC) to manage permissions for accessing specific documents or functionalities.
Kubernetes Orchestration: Migrate from Docker Compose to a Kubernetes (K8s) deployment for high availability, automatic scaling, load balancing, and resilient service management across multiple nodes.
Enhanced Resilience: Implement advanced circuit breakers, bulkhead patterns, and sophisticated retry budgets to handle transient failures gracefully and prevent cascading system outages.
Input Sanitization & Validation: Implement robust input sanitization and validation on all user-provided data to prevent common vulnerabilities like injection attacks and ensure data integrity.
Comprehensive Monitoring & Alerting: Beyond Phoenix for LLM traces, establish a full stack monitoring and alerting solution (e.g., Prometheus, Grafana, ELK stack) for infrastructure health, application performance, and security events.
These are some of the necessary steps to evolve from a functional demonstration to a battle-tested production system.
THE FUTURE: The Era of Sovereign Reasoning
What Comes Next? Glass Citadel is not a product. It’s a blueprint — one that prioritizes debuggability over magic, and ownership over convenience. The patterns here (structured ingestion, self-correcting agents, hybrid search with contextual linking) are not proprietary secrets. They are engineering choices available to anyone willing to reject the black box.
The architecture of Glass Citadel represents a shift in the way you ingest your data to later use it. As the cost of intelligence (tokens) drops to near zero, the differentiator is no longer “who has the best model,” but “who has the best context”. We are moving away from the era of “Prompting”—where we begged a distant god in the cloud to be smart for us—into the era of Sovereign Reasoning.
But architecture alone doesn’t guarantee success. The real test comes when you feed it your data — the messy, inconsistent, domain-specific corpus that no generic API was trained on.
That’s where sovereignty matters: when the model hallucinates, you can trace the thought. When the search fails, you can see why. When a vendor doubles their prices, you can swap them out by Tuesday.
This is not just about better search. It is about changing the relationship between humans and machines. We are stopping the parrot from squawking, and we are teaching the machine to think. The era of the Smart Parrot is ending. What replaces it is up to you. The full reference implementation is available at Glass Citadel GitHub repo (feel free to fork and submit PR’s). Start with the notebook, break something, and watch Phoenix show you exactly where it went wrong.
Welcome to the Citadel.
Peace. Stay curious! End of transmission.