
Why everything I've written is actually related to security
The patterns that make AI reliable—isolation, validation, controlled delegation—are akin to security patterns. Three months of AI architecture was the prerequisite. Now we go explicit.

A New Era for Next Kick Labs
Welcome to the next chapter.
I’ve rebranded. We’re now Next Kick Labs—same mission, sharper focus. You can find us at https://nextkicklabs.substack.com. Our updated tagline captures what this is about:
For the relentlessly curious. Learning the next big thing to master emerging tech. Securing it. Repeat.
That cycle—learning, building, securing—is what we’re committed to. The architecture deep-dives continue. The security frameworks will be more explicit. But now they’re unified under one clear purpose: help you master emerging tech before the vulnerabilities become disasters.
This article is the bridge. It’s where we make explicit what’s been implicit in everything I’ve written so far.
TL:DR;
I’ve spent three months writing about AI architecture. Agents. Memory. Sandboxing. Orchestration. That wasn’t a warm-up—it was the prerequisite.
You can’t secure what you don’t understand. And right now, security teams are being handed AI systems they’ve never seen the inside of, while AI teams are shipping agents with no framework for what could go wrong.
So I mapped my archive to security concepts—NIST, CSA, the frameworks that matter. The overlap is real: Firecracker VMs are isolation. Schema validation is input sanitization. Tiered memory is least privilege. Human-in-the-loop is approval workflows.
Same problems. Same solutions. Different vocabulary.
If you’ve been following along, you already have the foundation. If you’re coming from security, this is your map into AI. Either way, we’re ready to move forward.
The next articles go explicit: threat models, attack surfaces, and the patterns that hold.
The Itch: Why This Matters Right Now

I’ve been writing about AI for three months.
Agents. Memory tiers. Sandboxed runtimes. Schema validation. Orchestration protocols. If you’ve followed along, you’ve watched me build up a vocabulary for how these systems actually work—how they think, how they fail, how they recover.
That wasn’t random.
Here’s the thing: you can’t secure something you don’t understand. And most security teams right now are being asked to secure AI systems they’ve never seen the inside of. They’re handed a black box and told to make it safe.
That’s not security. That’s hope.
Meanwhile, AI practitioners are building agents that spin up their own compute, browse the web, execute code, and talk to each other—without any framework for thinking about what could go wrong. They’re optimizing for capability. Security is an afterthought, if it’s a thought at all.
I’ve been in enough rooms to see both sides struggling. Security people asking, “What even is an agent?” AI people shrugging, “We’ll figure out security later.”
The gap is real. And it’s dangerous.
So I went back through my archive. I mapped every article to security concepts—NIST, CSA, the usual frameworks. The result:
We have enough concepts to move forward into security for AI.
The Deep Dive: The Hidden Security Layer
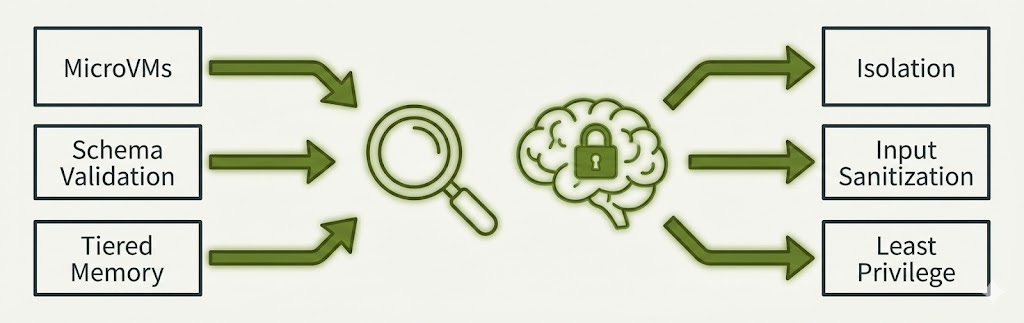
The Map
Not everything I wrote was security. But some of the core patterns? They translate directly.
ArticleWhat I Wrote AboutSecurity ConceptVirtualized WorkerFirecracker microVMs, sandboxingIsolation, blast radius containmentGlass CitadelPhoenix Arize observabilityAudit trails, loggingNeural ContractTiered memory (hot/warm/cold)Least privilege for contextNeural ContractSchema-driven summarizationInput validationNew ManagerScope of Work constraintsAccess control, guardrailsNew ManagerInterrupt ProtocolHuman-in-the-loop approvalAI ArchitectTask decompositionAttack surface reductionWorkslop TaxSystematic skepticismZero trust mindsetRAG UpgradeMulti-layer validationDefense in depthTwo-BrainOrchestration vs. generation splitSeparation of duties
Look at that table for a second.
If you’re from security, you recognize every term in the right column. Isolation. Least privilege. Defense in depth. Zero trust. These aren’t new concepts—they’re the bedrock of how we’ve protected systems for decades.
What’s new is the application.
Why This Wasn’t Obvious
Here’s the thing: when I wrote about Firecracker microVMs, I called it “sandboxing.” Security calls it “isolation.”
When I wrote about schema validation, I called it “stopping hallucinations.” Security calls it “input sanitization.”
When I wrote about tiered memory, I called it “keeping the model focused.” Security calls it “need-to-know access.”
Same problems. Same solutions. Different vocabulary.
The AI world reinvented security patterns because it had to. The failure modes forced it. An agent with unrestricted access will eventually do something catastrophic. A system without audit trails becomes a black box. A pipeline without validation will hallucinate garbage.
We arrived at isolation, observability, and validation not because we read NIST 800-207. We arrived there because the systems broke until we did.
The Translation Layer
Let me make a few connections explicit:
Firecracker microVMs = Microsegmentation.
In security, microsegmentation means dividing your network into isolated zones so a breach in one area can’t spread. In AI, we do the same thing with compute. Each agent gets a disposable VM. If it goes rogue, we burn it down. No lateral movement. The blast radius is one task.
Schema validation = Input sanitization.
Security teams have spent years building allow-lists and rejecting malformed input. In AI, we do the same thing with output schemas. The agent doesn’t return free-text; it returns structured JSON that validates against a spec. If the schema rejects it, the agent tries again. We’re not trusting the output—we’re verifying it.
Tiered memory = Least privilege for context.
Least privilege usually means “don’t give users access they don’t need.” With AI, it’s “don’t give the model context it doesn’t need.” The more you dump into the context window, the more confused it gets—and the more opportunity for sensitive data to leak into places it shouldn’t. Hot memory gets only what’s needed for the current task. Everything else stays in cold storage until explicitly retrieved.
Human-in-the-loop = Approval workflows.
When an agent hits uncertainty, it doesn’t guess. It pauses and asks a human. This is the same pattern as requiring manager approval for high-risk actions. The threshold is configurable. The principle is ancient.
The Resolution: What This Means for You
So what do you do with this?
If you’re a security professional wondering how AI fits into your world: you don’t need to learn a new discipline. You need to learn a new domain. The principles you already know—isolation, least privilege, defense in depth, zero trust—they all apply. What you need is the architectural context to apply them. That’s what these articles provide. Read the Virtualized Worker to understand sandboxing. Read the Neural Contract to understand memory and context. Read the New Manager to understand how delegation and access control work in agentic systems.
If you’re an AI practitioner who’s been building agents and workflows: you’ve been doing security work without calling it that. Now you have the vocabulary to talk to security teams. When they ask how you’re handling isolation, you can point to your Firecracker setup. When they ask about audit trails, you can show them your Phoenix traces. You’re not starting from zero—you’re translating.
If you’re a technical leader trying to govern both AI and security: stop treating them as separate problems. The same architectural rigor that makes AI systems reliable makes them secure. You don’t need two frameworks. You need one framework applied consistently.
What’s Next
I’m making this connection explicit from here on out.
The next articles will tackle AI security head-on: threat models for agentic systems, attack surfaces, prompt injection, credential theft, sandbox escape. The OWASP LLM Top 10. The patterns that break and the patterns that hold.
But the foundation is already laid. If you’ve been reading along, you’re not starting from scratch.
You’re just seeing the security layer that was there all along.
References
NIST SP 800-207 — Zero Trust Architecture. Foundational framework for least privilege, microsegmentation, and continuous verification.
NIST Cybersecurity Framework (CSF) — Core functions (Identify, Protect, Detect, Respond, Recover) that map to agentic system design.
Cloud Security Alliance (CSA) — Definitions and guidance for cloud-native security patterns, including isolation and data classification.
OWASP LLM Top 10 — Emerging framework for LLM-specific vulnerabilities (prompt injection, data leakage, insecure output handling).
Agache, A., et al. (2020) — “Firecracker: Lightweight Virtualization for Serverless Applications.” USENIX NSDI. The foundational paper on microVM isolation.
Peace. Stay curious! End of transmission.